One Question, One World
Qworld: Question-specific evaluation criteria for LLMs
About Qworld
Evaluating large language models (LLMs) on open-ended questions is difficult because response quality depends on the question's context. Binary scores and static rubrics fail to capture these context-dependent requirements. Existing methods define criteria at the dataset level or generate them in a single pass, which limits their ability to explore the evaluation space implied by each question.
This work introduces One-Question-One-World (Qworld), a method that generates question-specific evaluation criteria using a recursive expansion tree. Given a question, Qworld decomposes it into scenarios, perspectives, and fine-grained binary criteria through structured hierarchical and horizontal expansion. The resulting criteria specify what a high-quality answer must address for that question.
On HealthBench, Qworld covers 89% of expert-authored criteria and generates 79% novel criteria validated by human experts. Experts rate Qworld criteria higher in insight and granularity than those produced by prior methods. When applied to 11 frontier LLMs on HealthBench and Humanity's Last Exam, Qworld reveals capability differences in dimensions such as long-term impact, equity, error handling, and interdisciplinary reasoning that coarse rubrics do not distinguish.
By formulating criteria generation as structured coverage of question-implied evaluation axes, Qworld enables evaluation that adapts to each question rather than relying on fixed task-level criteria.
One question, one world of evaluation criteria
Qworld decomposes each question into scenarios, perspectives, and fine-grained binary criteria — building an evaluation world unique to that question.
Every question opens a new world
Different domains demand different lenses. Qworld discovers hundreds of fine-grained evaluation dimensions — each uniquely shaped by the questions it serves.
HealthBench
530+ dimensions from 200k+ question-specific criteriaHumanity's Last Exam
950+ dimensions from 100k+ question-specific criteriaBeyond expert-authored evaluation criteria
Expert-authored criteria on HealthBench span just 5 broad dimensions. Qworld's recursive expansion generates 45+ criteria per question, together it uncovers 530+ fine-grained evaluation dimensions, expert-clustered into 24 structured dimensions — exposing capability differences in crucial dimensions like long-term impact, equity, and privacy that coarse rubrics cannot distinguish.
Expert-authored evaluation criteria
5 dimensionsQworld-generated evaluation criteria
200k+ criteria· 530+ dimensions· 24 clustersFine-grained evaluation leaderboard
Model performance scored against Qworld-generated criteria — revealing capability differences across HealthBench and Humanity's Last Exam.
Per-question criteria explorer
Each question inhabits its own evaluation world. Select a question to see the tailored criteria Qworld generated through recursive expansion.
Select a question to explore its Qworld-generated criteria
Try Qworld yourself.
Generate question-specific evaluation criteria using the Recursive Expansion Tree. Enter any question and watch Qworld decompose it into scenarios, perspectives, and fine-grained criteria.
Demo not loading? The space may be sleeping. Try it directly on HuggingFace Spaces →
How Qworld works
A Recursive Expansion Tree that turns one question into a complete evaluation world.
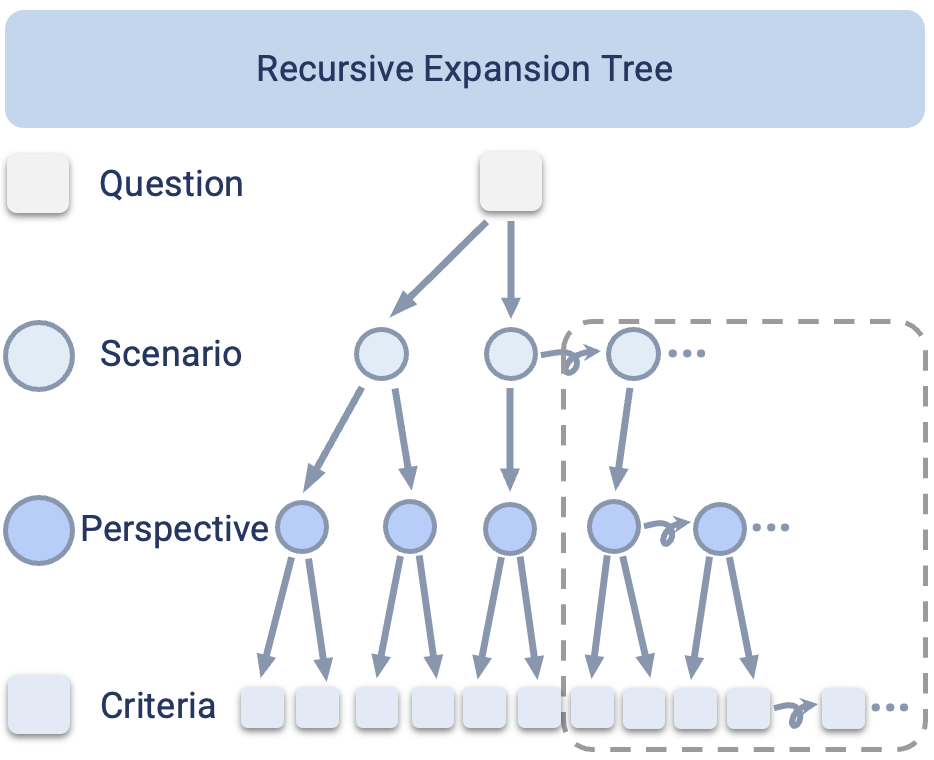
Scenarios
The distinct real-world contexts a question implies — each with its own intent, audience, and constraints.
Perspectives
The evaluation axes along which answer quality should be measured within each scenario.
Criteria
Specific, binary conditions with importance weights — 45+ tailored criteria per question.
Validate the quality of Qworld criteria
Qworld-generated criteria compared against four state-of-the-art methods on HealthBench, evaluated with both automatic metrics and human expert ratings. For more detailed quantitative results, refer to our paper.
| Method | Coverage ↑ | Uniqueness ↑ | Insight ↑ | Granularity ↑ |
|---|---|---|---|---|
| TICK | 0.46 | 0.24 | 0.20 | 0.90 |
| RocketEval | 0.53 | 0.26 | 0.42 | 0.94 |
| OpenRubrics | 0.54 | 0.37 | 0.36 | 0.54 |
| EvalAgent | 0.83 | 0.50 | 0.43 | 0.73 |
| Qworld | 0.89 | 0.79 | 0.83 | 0.96 |
Citation
@misc{gao2026qworldquestionspecificevaluationcriteria,
title={Qworld: Question-Specific Evaluation Criteria for LLMs},
author={Shanghua Gao and Yuchang Su and Pengwei Sui and Curtis Ginder and Marinka Zitnik},
year={2026},
eprint={2603.23522},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2603.23522},
}